
Regular Expressions
Match and extract text using regex
Regular expressions (regex) are a standard, well-documented way to match and extract text. In the context of Event Orchestration, you can use regex to determine event routing rules and define Event Fields. In the context of PagerDuty email integrations, you can use regex to fine-tune your email filters and email management rules.
Extract an Alert Key
You can use regex to modify the alert key to manage how alerts deduplicate. Regex can capture the full value of the matched text or a partial value by using a capture group.
You can follow the steps outlined in the Event Orchestration article to set a new deduplication key with regular expressions.
For email events sent to an email integration, you can set an alert key with a regular expression via the email integration's settings in the web app.

Use a regular expression to extract an alert key in an email integration
Capture Group
In regex, the definition of a capture group is anything between a set of parentheses, (...). A capture group tells PagerDuty to create an incident/alert key from the text between a set of parentheses, (...). If the unique identifier within the capture group is likely to change — for example, a numeric string such as a ticket ID or host ID — you can use \d+, which tells PagerDuty to capture all subsequent digits.
Similarly, if you want to capture a specific number of digits you could use \d to stand in place of each digit. For example, you could use \d\d\d\d or \d{4} if the unique identifier always contains four digits.
Capture Parentheses in the Unique Identifier
In some instances your unique identifier may contain parentheses. For example, Zendesk ticket IDs typically contain parentheses: This ticket (#27415) has been assigned to group 'Support', of which you are a member.

Unique identifier with parentheses
To capture the parentheses in a regex, use a backslash (\) before each parenthesis, for example: \(#\d+\). The backslash acts as an escape character that tells PagerDuty, "treat the following character as text."

Regular expression to capture parentheses
HTML Emails and Content Encoding
Email management regular expressions compare on the text of the email after decoding, per the encoding specified by Content-Transfer-Encoding. However, Content-Type is ignored.
If you decode a base64-encoded email and it has an underlying message in HTML (and there is no plain text copy of the email included), then the regex runs on the HTML code. It does not run on the text that would result after rendering the HTML or stripping out HTML tags.
This means that if you only send emails as HTML (Content-Type: text/html), regular expressions written to match the text content alone may not work. HTML tags, hidden line breaks, and whitespace can potentially interfere with your regular expressions' ability to match the input.
Read the Email Integration Troubleshooting Guide for more information.
Case Sensitivity
Regular expressions are case sensitive. This means "DOWN", "down", and "Down" are all considered different strings and do not all match against the same regex. You can make your email management rules case insensitive by adding (?i) to the beginning of the line, for example: (?i)(critical)
This captures all cases: "critical", "CRITICAL", and "cRiTicAL".

Case-insensitive regular expression
TipThe case insensitivity modifier
(?i)works in email management rules, however it is not supported with email filters. With this in mind, use a pipe character (|) to capture different upper/lowercase strings for email filters, for example:(Down|DOWN|down)For Event Orchestration rules, comparisons are case-insensitive by default, however this can be overridden when using the PagerDuty Conditional Language (PCL).
Test Your Regex
To compose, edit, and test your regular expressions, use Regex101.
To test a regular expression in Regex101, enter your test string — in this example, you want to extract the node A74U-138 from the email body and use it as the incident/alert key — and make sure that the regex shows a Group 1 match.
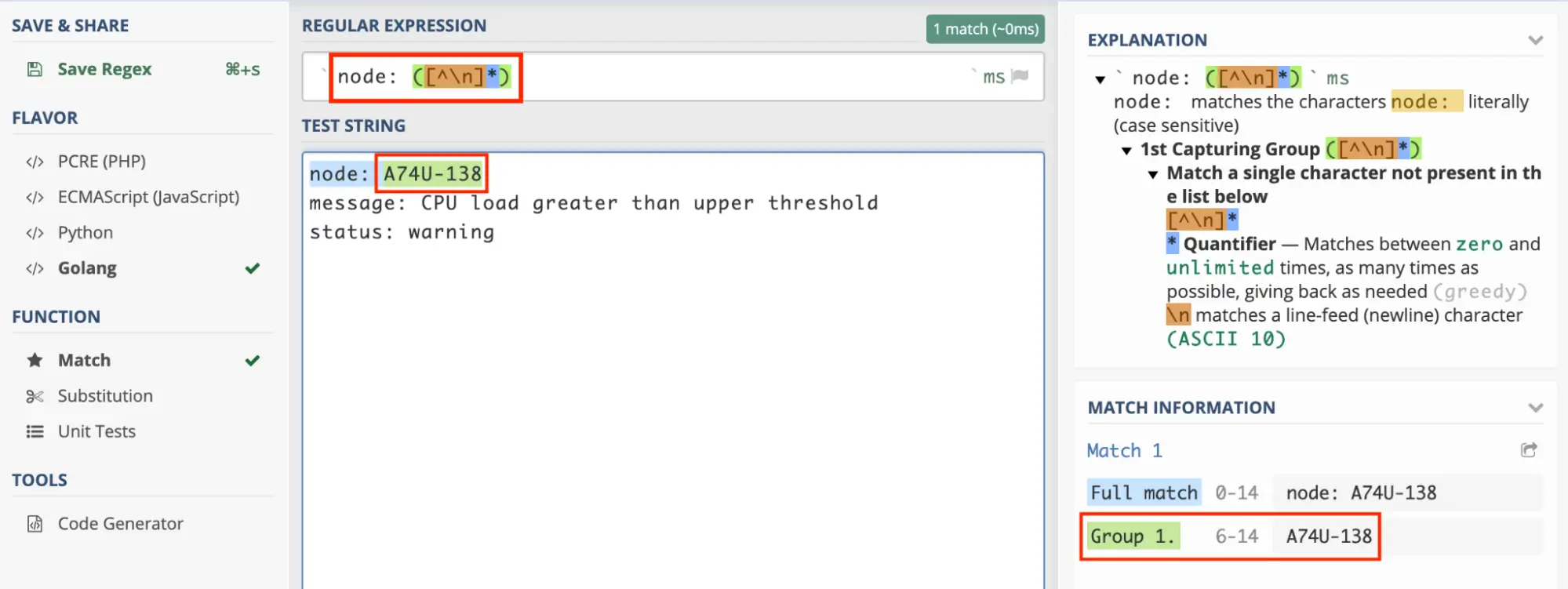
Test your regex
Regex Testing TipWhen using the external site Regex101 to test your regex, select the following options:
- Golang flavor
- multi line
- single line
If your regular expression matches on the sample text you enter into Regex101, it should work for the same text in PagerDuty.
Capture Group Implementation
PagerDuty's email management rules use Google's RE2 for regular expression handling, and additionally adds some custom behavior. Some specific things to be aware of:
- Nested capture groups are not supported. The following regular expression generates an error when saving the service:
(([0-9])[0-9]). - If you define multiple capture groups, PagerDuty concatenates the captured material in each group together, using a
-character. For example, if you match([a-z])([a-z])againstab, PagerDuty extracts this asa-b. - Two options are always added to your regular expression (documented in the RE2 documentation) when extracting data:
s(single-line mode) means that the.special character also matches newlines (\n).m(multi-line mode) causes^and$to match the beginning and end of lines, in addition to the beginning and end of the entire text.- A consequence of these two behaviors and regex greediness is that
(.*)$matches everything until the end of the document. Use([^\n]*)to match everything until the end of the line.
Examples
The following is an example of a common use case using a regular expression in the context of an email integration:
Your PagerDuty service receives emails from a monitoring tool, however you only want to trigger incidents if the subject line starts with "CRITICAL" or "SEVERE". The regular expression you would use to match incidents of this type would be: ^(CRITICAL|SEVERE).
The ^ character means the subject line starts with this, and (CRITICAL|SEVERE) means the starting word can be either "CRITICAL" or "SEVERE".
Other Common Regex Examples
| Filtering For | Filter Options and Regular Expression |
|---|---|
| "Open Escalations" or "[JIRA] Commented:" | Open Escalations|\[JIRA\] Commented: |
- All emails that contain "Priority 1" or "Priority 2" and "Failed" in the subject - AND contains "Warning to Failed" or "Normal to Failed" in the message body - AND only accepts emails from [email protected] | - The email subject matches the regex: (?:Priority 1|Priority 2).*Failed - AND the email body matches the regex: Warning to Failed|Normal to Failed - AND the from address exactly matches: [email protected] |
| Only trigger incidents from specific domains | The email from address matches the regex: domain1.com|domain2.com|domain3.com|domain4.com |
| Filter out email replies that include "RE:" or "FWD:" at the beginning of the emails | The email subject does not match the regex \A(?:RE:|FWD:) |
Updated about 1 month ago