
Configurable Service Settings
Customize the incidents' behavior on a service
Service settings allow you to customize what actions you would like performed when an incident is triggered. Service settings address incident assignment and notifications, noise reduction, coordinating with stakeholders, event rules, and remediation resources. By configuring these settings, you can optimize each incident to address your team's specific needs.
Required User PermissionsYou can edit services if you have one of the following roles:
- User
- Admin
- Manager base roles and team roles
- Manager team roles can only manage services associated with their team.
- Global Admin base roles
- Account Owner
Add an Incident Workflow to a Service
You can configure a service to run an Incident Workflow when an incident triggers and conditions are met.
- Navigate to Services Service Directory and select your preferred service.
- Select the Workflows tab and click Associate Workflow.
- Follow the steps in the Incident Workflow guide to create or edit a workflow.
Remove an Incident Workflow from a Service
To remove an Incident Workflow from a service:
- Navigate to Services Service Directory and select your preferred service.
- Select the Workflows tab and click next to the workflow you want to remove.
- Click Open in builder and remove the association with the service.
Assign to Escalation Policy
Every service in PagerDuty is associated with an escalation policy. You can assign a different escalation policy to a service with these steps:
- In the PagerDuty web app, go to Services Service Directory and select the service you want to edit.
- Select the Settings tab and click Edit to the right of Assign and Notify.
- In the Assign to escalation policy dropdown, select an escalation policy.
- Click Save Changes.
Notification Urgency
Configuring for Business Hours Only?To send high-urgency, paging notifications only during business hours (also called office hours or working hours) see the Urgency Use Case: Support Hours option below. You define the days, hours, and time zone for your support hours, then choose which notification urgency applies during and outside those hours.
This does not stop incidents from being created outside business hours — it changes how responders are notified. For quiet after-hours behavior, the service's support-hours urgency works together with each responder's notification rules: set outside-hours incidents to low urgency, and make sure responders' low-urgency rules are quiet (or off).
PagerDuty uses the concept of urgency to allow you to customize how responders are notified depending on how critical an incident is. Incidents can be either high-urgency (it requires immediate attention) or low-urgency (it can wait).
As an incident responder, this means you can set up notification rules so that you are not woken up for low-urgency incidents that can be handled in the morning, or you can set a service to notify you with only high-urgency or low-urgency notification methods at specific times of day.
Low-Urgency Incident EscalationIn contrast to high-urgency incidents, low-urgency incidents do not automatically move to higher escalation levels if no one acknowledges them. Low-urgency incidents also cannot be manually escalated, only re-assigned. If you need to escalate a low-urgency incident according to the escalation policy on that service, you must change it to high-urgency first.
There are two steps that go into effectively using urgencies:
Step One: Configure Urgencies on a Service
Urgencies are defined on a service, and all services initially default to High-urgency notifications, escalate as needed.
To adjust a service's urgency:
- In the PagerDuty web app, go to Services Service Directory and select the service to edit.
- Select the Settings tab and click Edit to the right of Assign and Notify.
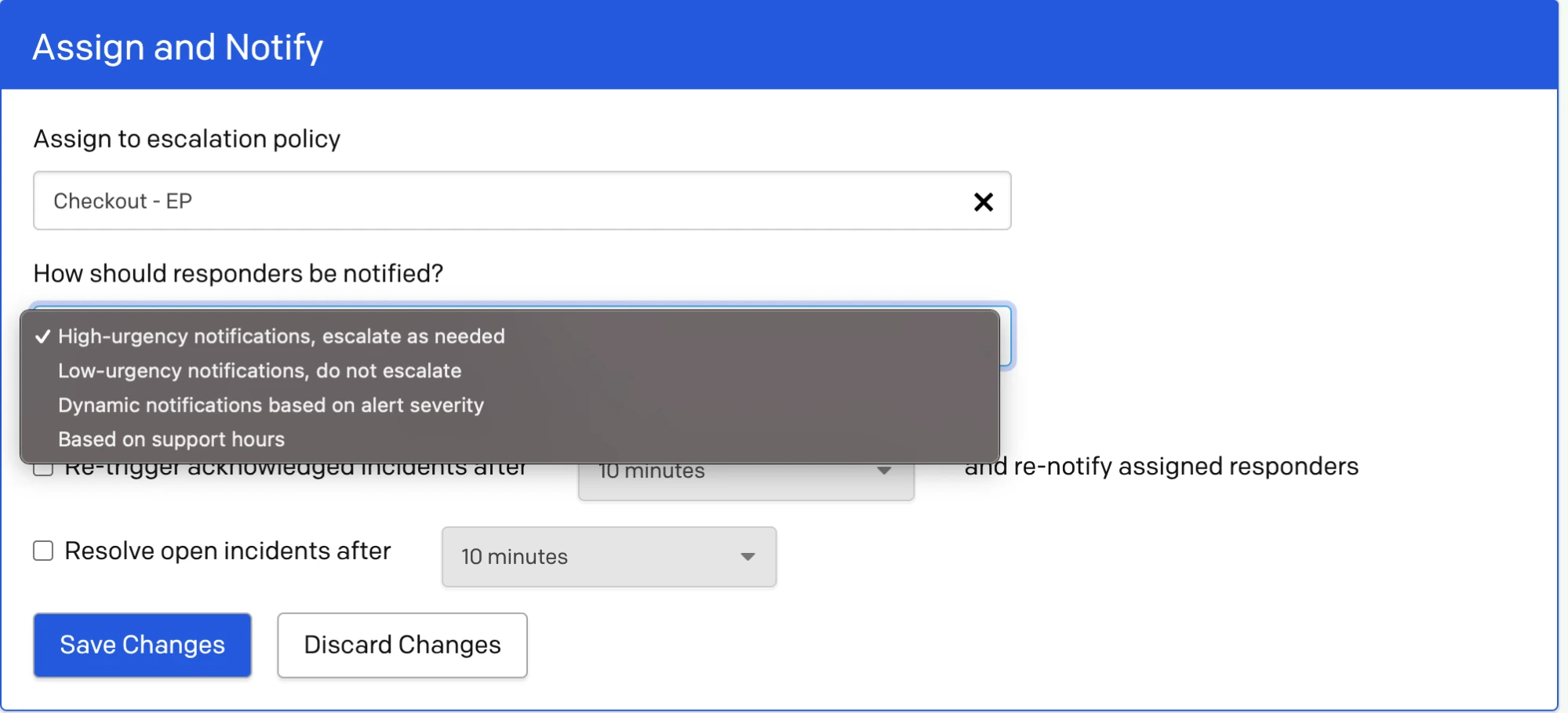
- Under How should responders be notified?, select one of the following options (depending on your account's pricing plan, some of these options may not be available):
- High-urgency notifications, escalate as needed
- Low-urgency notifications, do not escalate
- Dynamic notifications based on alert severity
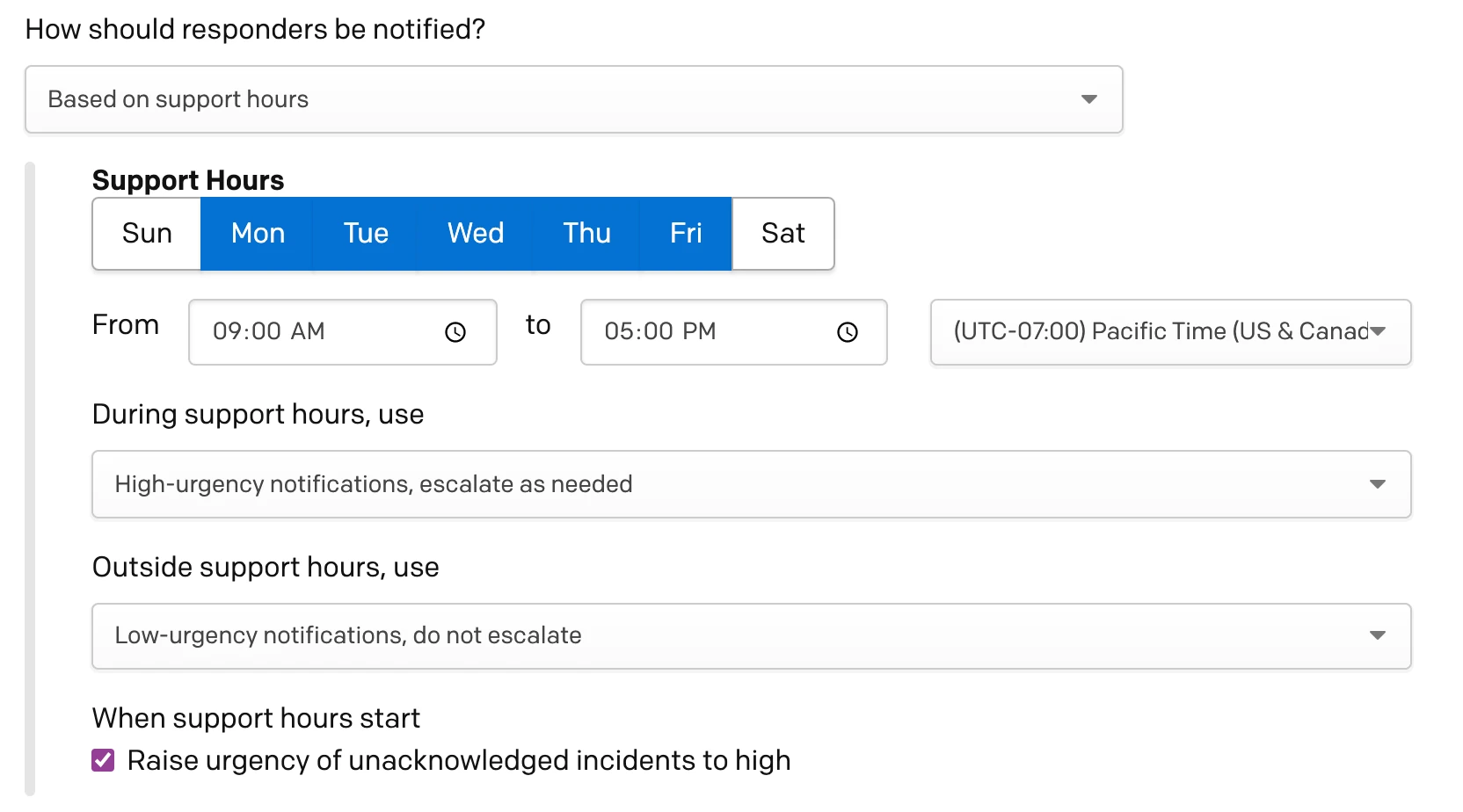
- Based on support hours: Once selected, select the days of the week and the hours and time zone for your support hours. Next, under During support hours, use, select what type of notification urgency you would like during support hours. Under Outside support hours, use, select what type of notification urgency you would like outside of support hours. You may also optionally choose to check the box next to Raise urgency of unacknowledged incidents to high when support hours start.
- Click Save Changes.
Select notification urgency
Manually Setting UrgencyIf an incident's urgency is set either in the web or mobile app or through the REST API when an incident is triggered, then the selected urgency level overrides whatever urgency setting is set on that service.
Step Two: Configure User Profiles
After you have configured urgency on a service, responders specify their notification urgency preferences on their user profile.
Create several tiers of "noisy" notification rules for high-urgency incidents so that on-call responders are notified numerous times until they acknowledge the incident.
For low-urgency incidents, however, an on-call responder may want to receive "quieter" notifications, like a push notification or email, or even no notification at all.
For more information, see Notification Rules.
Urgency Use Case: Support Hours
Consider a support team as an example. Since a support team responds to customer inquiries during business hours, you may want incidents to be categorized as critical during business hours and non-critical after hours.
The following options are available both During support hours and Outside support hours:
- High-urgency notifications, escalate as needed
- Low-urgency notifications, do not escalate
- Dynamic notifications based on alert severity
Beneath your support hours there is an option When support hours start, raise urgency of unacknowledged incidents to high. With this feature enabled, all open incidents on the service become high-urgency when your support hours begin, and responders receive notifications based on their high-urgency notification rules. Notifications continue until a responder acknowledges or resolves the incident.
Set support hours Monday through Friday, 9:00 a.m. to 5:00 p.m.
This setting is useful for teams who rely on support hours to give their people a rest during off-hours, but want to make sure that any incidents that trigger outside of business hours are promptly handled once business hours begin again. Note that the From and to times are for each day. If you select two or more continuous days, then the start and end times apply to each day individually.
Manually Triggered IncidentsWhen manually triggering a PagerDuty incident in the web app, it is possible to make an urgency selection that overrides the service's support hours settings.
Edit Urgency
If an open incident's urgency has been reassessed, responders can edit its urgency in the web or mobile app. Read Edit Incident Urgency for more information.
Acknowledgement Timeout
Incident acknowledgement timeouts help ensure that an acknowledged incident is not forgotten. This feature is turned off by default.
With this feature enabled, an acknowledged incident re-triggers after a specified amount of time. When the incident re-triggers, it re-notifies assigned responders and, if on-call responsibilities have rotated, the current on-call responder, too.
You can configure the timeout's length, or turn it off completely, on the service's settings page:
- Go to Services Service Directory and select the service you want to edit.
- Select the Settings tab and click Edit next to Assign and Notify.
- Enable the checkbox Re-trigger acknowledged incidents after [TIME] and re-notify assigned responders and select the timeout period from the dropdown.
- Click Save Changes.
If you need to set the timeout to a value that is not offered in the web app, you may also adjust it using the REST API.
Snooze an IncidentIf you need to quiet an individual incident for a different length of time than the service's incident ack timeout, you can snooze the incident instead.
Auto-Resolution
If you would like an incident to automatically resolve after a given amount of time, you can set a service to auto-resolve incidents. By default, this feature is not turned on.
Auto-resolution is recommended for services that are expected to produce a high number of active incidents, or for monitoring systems that send trigger events but not resolve events (for example, some email-based monitoring systems).
This feature can be useful when there are a large number of active incidents on a service (such as in a CentralOps/NOC environment), because if an incident is not resolved automatically by a monitoring system or manually by a responder, responders may not be aware of any recurrences of the issue.
With this feature enabled, an incident automatically resolves after the specified time has passed, and no further notifications are sent for the incident.
Note that an incident contributes to the auto-resolution timer as long as it is in a triggered or acknowledged state. Snoozed incidents reset the auto-resolution timer.
Also note that this feature only affects incidents that are created after it is enabled and does not retroactively resolve incidents that are currently open.
High Open Incident VolumeFor services with over 100,000 open incidents, PagerDuty automatically enables and requires the auto-resolve feature to be enabled. When this feature is enabled, all new incidents for that particular service are auto-resolved after they have been open for 24 hours, and no further notifications are sent for those incidents.
It is not possible to disable this feature for the service in question unless the service's open incident count is reduced to under 100,000. To reduce the open incident count, use the update an incident API to bulk resolve incidents. Additionally, you can use this script for an automated way to bulk resolve incidents.
Configure Auto-Resolution
- Go to Services Service Directory and select your preferred service.
- Select the Settings tab and click Edit next to Assign and Notify.
- Mark the checkbox Resolve open incidents after [TIME] and select a time period from the dropdown.
- Click Save Changes.
If you need to set this to a time period that is not available in the web app, you can do so with the REST API.
Turn Off Auto-Resolution
- Go to Services Service Directory and select your preferred service.
- Select the Settings tab and click Edit next to Assign and Notify.
- Unmark the checkbox Resolve open incidents after [TIME].
- Click Save Changes.
Manage AIOps
AIOps Service Configuration provides you with flexibility and control over how and where AIOps features apply. This feature allows you to enable or disable AIOps on services. See the PagerDuty AIOps article for more information.
AvailabilityThis feature is in Limited General Availability with the PagerDuty AIOps add-on. Contact your account team or Support to request access. To sign up for a trial of PagerDuty AIOps features, read PagerDuty AIOps Trials.
Required User Permissions
- Account Owner
- Admin and Global Admins
- Manager base role and team roles
- Manager team roles can only manage services associated with their team
Disable BehaviorNote that when you disable AIOps Service Configuration on a service, you can expect the following to occur:
- Event Throughput: If an AIOps integration key requests an increased throughput and you subsequently disable AIOps, it defaults back to a maximum of 120 events/min.
- Operations Console: Only incidents created on an AIOps service are visible.
- Incidents: The following features are no longer available on the service's incidents:
- Outlier Incident
- Probable Origin
- Past Incidents
- Related Incidents
- Recent Changes
- Noise Reduction: The following service features are disabled, with any relevant data used to enhance the models deleted.
- Auto Pause
- Alert Grouping
- Recent Changes:
- The system blocks non-AIOps services from creating integrations on the Recent Changes page.
- The system hides Recent Changes on the Service Activity tab.
- AIOps Service Orchestration Rules: Only AIOps-enabled services have access. The system skips any existing rules using AIOps-required functionality during event ingestion.
- Routing to AIOps-Enabled Services Using an Event Orchestration: Only AIOps-enabled Event Orchestrations can route to AIOps-enabled services. If a non-AIOps Event Orchestration has an invalid routing rule that routes to an AIOps service, the event still routes to the service to ensure it does not miss an incident. However, this incident has all AIOps features disabled, including skipped Orchestration rules. This may result in unintended consequences such as increased noise.
- Navigate to Services Service Directory.
- Select your preferred service and open the Settings tab.
- Under the AIOps section, perform the following based on your use case:
- Click Enable AIOps. In the confirmation modal that appears, click Enable to complete the process.
- Click Disable AIOps. In the confirmation modal that appears, click Disable to complete the process.
Alert Grouping
Alert Grouping allows you to configure a service to group alerts in a variety of ways, thereby reducing noise and accelerating teams' responses.
Pricing PlanAlert Grouping is available with the PagerDuty AIOps add-on. The feature is also available for the duration of an AIOps trial. Contact the Sales Team to upgrade to a pricing plan with this feature.
To configure a service's Alert Grouping behavior:
- Go to Services Service Directory and select your preferred service.
- Select the Settings tab and click New Grouping or Edit in the section Reduce Noise.
- Select one of the following options:
- Intelligent
- Alert Content
- Time only
- Click Save Settings.
Read more about each Alert Grouping option:
- Intelligent Alert Grouping
- Content Based Alert Grouping
- Global Alert Grouping
- Time Based Alert Grouping
Auto-Pause Incident Notifications
Automatically pause notifications for transient alerts, giving time for them to resolve before distracting responders.
AvailabilityThis feature is available as part of the following pricing plans: Digital Operations (legacy) and Enterprise for Incident Management, or it can be purchased via the AIOps add-on. You can trial PagerDuty AIOps or contact the Sales team to try this feature.
To configure Auto-Pause Incident Notifications on a service:
- In the PagerDuty web app, go to Services Service Directory and select your preferred service.
- Select the Settings tab and click Edit next to Reduce Noise.
- In the section Transient Alerts, select Auto-pause incident notifications and make a selection from the dropdown:
- 2 minutes
- 3 minutes
- 5 minutes
- 10 minutes
- 15 minutes
- Click Save Changes.
For more detailed information about this feature, see Auto-Pause Incident Notifications.
Add a Conference Bridge
You can configure a service to include a Conference Bridge on every incident. PagerDuty supports dial-in numbers and meeting URLs.
- Go to Services Service Directory and select your preferred service.
- Select the Settings tab and click Edit next to Coordinate Responders and Stakeholders.
- In the fields Conference Bridge Dial-In Number and Conference Bridge Meeting URL, enter your conference bridge information.
- Click Save Changes.
Event Management
Event Management can be configured at two different levels: at the service level and at a global level. For more information, see the Event Orchestration article.
Documentation Link
You can add a link to documentation that includes routine procedures or troubleshooting steps for a service so that it can be easily referenced during an incident.
- Navigate to Services Service Directory and select your preferred service.
- Select the Settings tab, scroll to the section Remediate, and click Edit.
- In the field Documentation link enter the full path of the link to your documentation.
- In the field Documentation link name, enter a user-friendly description.
- Click Save Changes.
Once configured, responders can view the documentation link in the same section on a service's details page under Settings Remediate.
Delete a Documentation Link
- Navigate to Services Service Directory and select your preferred service.
- Select the Settings tab and click Edit to the right of Remediate.
- Click Remove Documentation.
Custom Incident Actions
Custom incident actions provide responders with a quick way to execute custom logic housed outside of the PagerDuty system. For more information, refer to Custom Incident Actions.
Updated 3 days ago